1.1.1. DataStream API
DataStream API 用来对数据流进行摄入,过滤,更新,聚合等一系列操作。数据来源可以是多种多样的(比如静态文件,消息队列,socket 流等)。数据流处理的结果流向 sink,比如写数据到文件或者输出到标准输出。Flink 程序跑在多种上下文环境中,standalone 或者嵌入在其它程序中。程序可以执行在一个本地 JVM 进程,也可以运行在拥有多台机器的集群上。
1.1.2. 什么是 DataStream
DataStream API 得名于 Flink 内部实现的数据集合类-DataStream。你可以认为 DataStream 是一种可以包含重复数据的数据集合,这些数据可以是有界和无界的,其处理 api 是相同的。emmn,这里也说明 Flink 统一了流批 api,都可以使用 DataStream 来对数据进行操作。
DataStream 类似于 Java Collection,但是在一些核心方法上有所不同。DataStream 是不可变的,这意味着它一旦创建便不能更新,并且不能直接检查元素,只能依靠 DataStream API 提供的 operator 进行操作,这些 operator 也叫作 transformations。
1.1.3. Flink 程序剖析
Flink 程序通常由以下几部分组成:
- 创建执行环境,及 Execution Environment。
- 从外部数据源加载或者直接创建初始数据。
- 指定初始数据流后续的转换操作。
- 指定 sink,即计算结果该输出到什么地方。
- 触发程序的执行。
下面会详细的介绍这几步过程。DataStream 的核心类都可以在 org.apache.flink.streaming.api 中找到。
StreamExecutionEnvironment 是 Flink 程序的入口,可以通过以下方法创建
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String... jarFiles)
通常,你只需要使用 getExecutionEnvironment(),Flink 会根据上下文创建合适的执行环境:如果你在 IDE 中运行,那么就会创建 local environment 用以在本机执行程序。如果你将程序打成 jar 包并且通过命令行提交,那么 Flink 集群管理器会执行 main 方法并调用 getExecutionEnvironment(),返回一个集群下的执行环境。
env 中的一些方法可以用来指定 source。如果要读取文件的话可以采用以下代码:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");
这会创建 DataStream,接下来就可以在上面应用一些转换操作,得到新的 DataStream。比如下面对每行数据转 int。
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
一旦 DataStream 完成最终的操作,就可以 sink 到外部系统中。
writeAsText(String path)
print()
在完成以上程序后,需要通过 env.execuet() 方法触发程序的执行。execute 是同步的,需要等待程序执行完成返回最终结果。如果你不想等待 job 的执行就退出,那么可以使用 executeAysnc() 方法,它会返回一个 jobClient,用以与程序通信。比如,下面的代码使用 executeAysnc 来实现 execute 一样的功能。
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
Flink 程序都是惰性执行的:当程序的 main 方法被执行时,数据的加载和转换并不是立刻发生的,而是先生成 job graph。当执行调用 execute 时,这些操作才被真正的执行。惰性执行可以使我们构建复杂程序作为一个完整单元执行。
1.1.4. 示例
下面是一个 wordcount 程序,首先命令行启动 nc -lk 9999,在启动 Flink 程序,命令行输入单词,就会看到程序的 标准输出。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
1.1.5. Data Sources
Source 是指程序能够从哪里读取数据,你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来添加自定义数据源。Flink 内部已经定义了一些简单数据源,但是还是经常需要通过 SourceFunction 来自定义实现非并行数据源,通过 ParallelSourceFunction 和 RichParallelSourceFunction 来定义并行数据源。
从 StreamExecutionEnvironment 可以访多个预定义的数据源。 基于文件的:
- readTextFile(path) - 读取文本文件,符合 TextInputFormat 格式的文件,逐行读取并作为字符串返回。
- readFile(fileInputFormat, path) - 指定 fileInputFormat 读取文件。
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个方法内部调用的方法,按照给定的 fileInputFormat 读取 path 路径下的文件。如果
watchType=FileProcessingMode.PROCESS_CONTINUOUSLY,则会定时监控是否有新数据进来并处理。如果watchType=FileProcessingMode.PROCESS_ONCE,则程序只会读取当前文件内容,处理完成后就会退出。pathFilter 用于排除一些文件。执行过程: Flink 会启动两个 subtask 来执行,及目录监控和数据读取。监控 task 是非并行的,读取 task 会切分成多个任务来并行执行,后者的并行度等于 job 的并行度。监控任务的作用是扫描文件(根据 watchType 扫描一次或者多次),找到待处理的文件,根据配置划分成各个分片发送给下游 reader 读取。每个分片只能被一个个 reader 读取。一个 reader 可以读取多个分片,只不过是串行的。
注意事项
- 如果
watchType=FileProcessingMode.PROCESS_CONTINUOUSLY,文件被更改会造成整个文件内容被重新处理,这破坏了精确处理一次的语义。向文件后面追加数据也会造成重复处理整个文件。 - 如果
watchType=FileProcessingMode.PROCESS_ONCE,只会扫描一次数据源就会断开与其的连接,这会造成后续没有 checkpoint 的产生,在任务失败重新恢复时会从一个相对较老的 checkpoint 恢复,因此 failover 的时间会变长。
- 如果
基于 socket:
- socketTextStream,读取 socket 流。
基于集合的:
- fromCollection(Collection) - 从
Java.util.Collection中创建 datastream,集合中的元素类型必须是相同的。 - fromCollection(Iterator, Class) - 从迭代器中创建 datastream,Class 表示迭代器返回的元素类型。
- fromElements(T ...) - 从给定的序列中创建 datastream,序列中的元素要求相同类型。
- fromParallelCollection(SplittableIterator, Class) - 从并行的迭代器中创建 datastream,Class 表示迭代器返回的元素类型。
- generateSequence(from, to) - 创建指定范围内的序列,依据此序列创建 datastream。 自定义:
- addSource - 实现一个新的 sourceFunction,比如 Kafka,就是
addSource(new FlinkKafkaConsumer<>(...)).。这里需要阅读下 connector 章节。
1.1.6. Data Sinks
Data sinks 消费 DataStreams 并将他们输出到文件,sockets,外部系统或者标准输出中。Flink 已经内置了一些 sink。
- writeAsText() / TextOutputFormat
- writeAsCsv(...) / CsvOutputFormat
- print() / printToErr() - 如果是并行输出,会输出每个 subtask 的标号。
- writeUsingOutputFormat() / FileOutputFormat
- writeToSocket
- addSink 需要注意类似 write*() 的方法往往用于调试。它们不参与 Flink 的 checkpoint,这意味着这些方法只支持至少处理一次语义。数据写入到目标系统取决于使用的 OutputFormat,可能是打满 buffer 后在落盘,因此数据不会立刻刷入到目标系统中。同样的,如果任务失败,存在着丢数的风险。
要使用具有可靠性,精确处理一次语义特性的话,可以使用 StreamingFileSink。使用 addSink 方法实现的 sinks 也会参与 checkpoint。
1.1.7. Iterations
这里主要讲的是 Iterative Stream,一开始没太搞明白,直接看下面这张图会更清晰点。迭代流需要实现何时将流返回,何时将流发往下游。
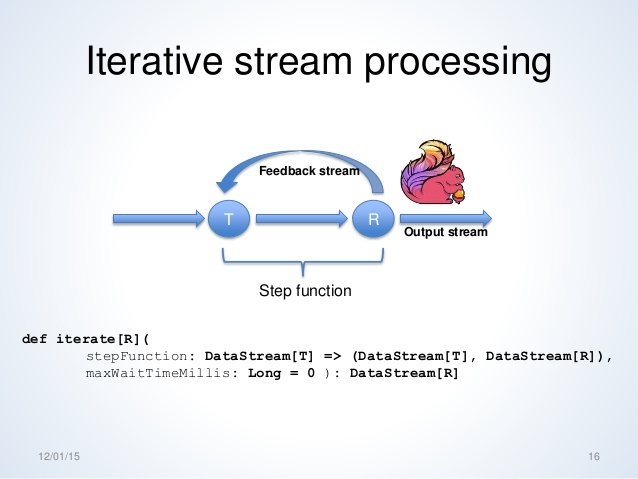
1.1.8. 执行参数
StreamExecutionEnvironment 可以设置 Flink 程序运行时的一些配置信息。可以查看 execution configuration 了解更多。
容错管理
State & Checkpointing 描述了如何开启并配置 Flink checkpoint。
延迟控制
数据流在传输中为了避免不必要的网络流量,都会先缓存数据。在 Flink 配置文件中可以设置该 buffer 的大小,这样可以提高程序吞吐量,但是在上游数据 qps 不高的情况下,会增大数据的延迟。因此,为了衡量吞吐量和延时,可以设置 buffer 填满的最大等待时间,如果时间到了,buffer 仍然未被填满,那么就不在等待而是直接发送数据到下游。默认的超时时间是 100ms。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
为了最大化吞吐量,可以使用 setBufferTimeout(-1) ,在 buffer 未被填满的情况下不会像下游发送数据。为了最大化延迟,可以使用 setBufferTimeout(0),但是会导致严重的性能问题。
1.1.9. 调试
在将程序部署到正式分布式环境前肯定需要调试验证程序的可用性,这里讲的就是如何在本地简单调试。但是其实在工作中,往往受限于各种代理问题,无法本地连上某些服务,比如 Kafka 等,因此往往需要走 CI 打包到开发机上运行在调试。以下这些方法个人认为比较适合做实验,就像 Spark 的 Seq(...).toDF() 等。
Local Execution Environment
创建本地执行环境,类似 Spark Local,就是 JM,TM 啥的都在一个进程里。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
// build your program
env.execute();
Collection Data Sources
从 java 集合中创建 datastream,方便用于测试数据。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// Create a DataStream from a list of elements
DataStream<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataStream from any Java collection
List<Tuple2<String, Integer>> data = ...
DataStream<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// Create a DataStream from an Iterator
Iterator<Long> longIt = ...
DataStream<Long> myLongs = env.fromCollection(longIt, Long.class);
需要注意集合数据类型需要实现对应的序列化方法。Collection Data Sources 的并行度是 1。
Iterator Data Sink
如果是为了调试的话,感觉输出到标准输出或者文件都挺好的。官网这里建议可以使用迭代器,将结果收集到一个迭代器中,在做后续处理,不管是查询还是输出。
import org.apache.flink.streaming.experimental.DataStreamUtils
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = DataStreamUtils.collect(myResult)
1.1.10. 思考
1. 创建执行环境时的上下文指的是啥?
在 org.apache.flink.streaming.api.environment 可以找到入口函数,然后就开始点点点看源码中的获取过程。
public static StreamExecutionEnvironment getExecutionEnvironment(Configuration configuration) {
return Utils.resolveFactory(threadLocalContextEnvironmentFactory, contextEnvironmentFactory)
.map(factory -> factory.createExecutionEnvironment(configuration))
.orElseGet(() -> StreamExecutionEnvironment.createLocalEnvironment(configuration));
}
2. setBufferTimeout 方法是 operator 级别还是 env 级别的?
这块需要测试下,以 binlog 为例,统计到某个 operator 时的端到端延迟。